[Paper Summary] Beyond English-Centric Multilingual Machine Translation by Facebook AI
Summary of MTM Paper: Data Preparation (Page 1-16)
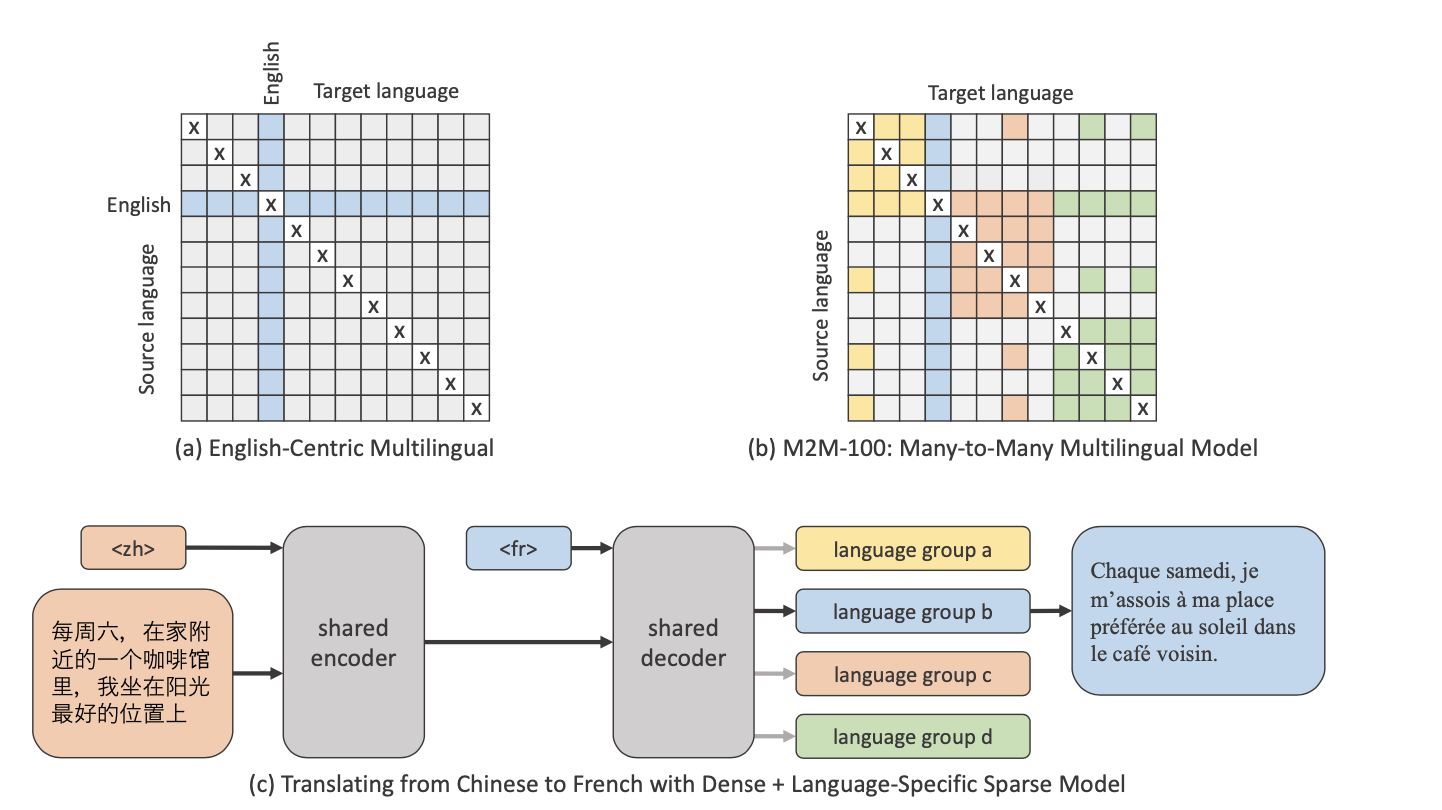
Summary of Many-to-Many dataset and multilingual model. English-Centric data (top left) only contains training data to and from English, where as Many- to-Many multilingual setting (top right) contains data directly through various different directions.
Arxiv Paper: Beyond English-Centric Multilingual Machine Translation by Facebook AI
Code: https://github.com/pytorch/fairseq/tree/master/examples/m2m_100
Since this is a very long paper, I have divided the summary into 2 posts:
- Data Preparation [This post]
- Model Training [Link]
Multilingual Translation Model (MTM)
Aim of MTM: Build a single model to translate between multiple languages.
Problems of MTM: Performance not at par with Bilingual Models when trained on same languages. Ex: Model trained separately on Hindi-Bangla would perform better than MTM with Hindi-Bangla as one of the pairs among many languages.
Reason: Model capacity splits between multiple languages.
Solution: Increase model capacity.
Problem with increased capacity: Large models require large multilingual datasets which are not easy to obtain. Ex: Low availability of parallel data between Hindi-Bangla.
Solution: Use english as pivot language. Learn models from Hindi-English and English-Bangla to convert Hindi-Bangla.
Problem with using English-centric conversion: English-centric bias does not represent real-world usage of the language and hence, low performance. Ex: A person speaking Tamil and Hindi does not use English as a medium of conversion between those languages.
Hence, this work by Facebook AI aims to learn a single MTM for non-english translation directions without using English as a pivot language.
Novelty: Automatic construction of parallel corpora using data-mining and semantic similarity. First Many-to-Many dataset with 7.5B training sentences for 100 languages => Direct training data for thousands of translation directions (100*99=9900 directions).
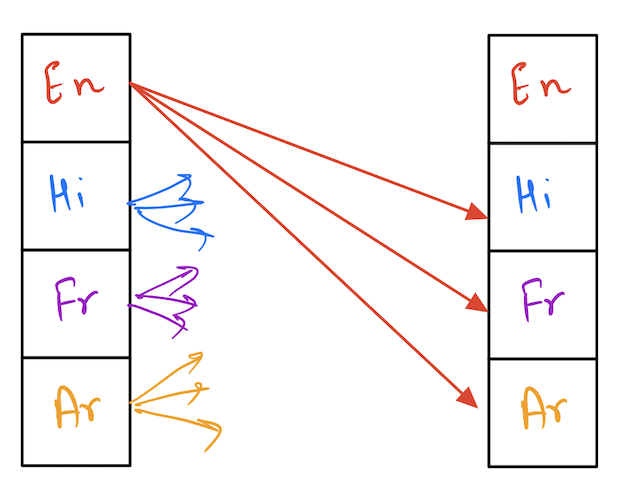 4 X 4 Languages need translation models from 4*3 = 12 Directions
4 X 4 Languages need translation models from 4*3 = 12 DirectionsProblem with increase in no. of languages: Quadratic increase in dataset.
Ex: 3 Languages: 3*2 =6 directions. 4 languages: 4*3= 12 directions. => Model prone to underfitting. Paper proposes several scaling strategies to solve this problem.
For basics of seq-to-seq machine translation models refer to : Visualising NMT
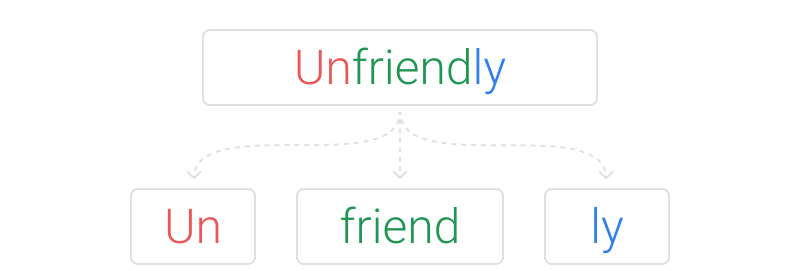
Sub-word based tokenization
Seq-to-seq models requires a sequence of tokens as input and output. These tokens can be words, characters, sub-words etc. Providing complete words as tokens leads to large vocabularies or poor coverage. Ex: The english dictionary will have multiple forms of the root word “play” i.e. playing, played, etc. Hence, sub-word tokenization is preferred over word-based tokens. For detailed introduction to tokenization refer Tokenization Summary. This paper uses Sentencepiece tokenization as it was designed to work with languages with no segmentation.
Problem with SentencePiece: Generates sub-word units based on frequency in train set => Rare words & words in low-resource language less likely to be sampled.
Solution: Add monolingual data to train set to create the dictionary. Final dictionary contains 128k unique tokens that are well distributed across languages.
Model details
- 12 Encoder - 12 Decoder layers, with 8192 FFN size and 1024 embedding dimension.
- Parameter Count: 1.2B
- Weight matrices of the input and output embeddings shared.
- Adam optimizer, warmup for 4000 updates with label smoothing 0.1 .
- For regularization, dropout parameter tuning between {0.1, 0.2, 0.3}.
- To stabilize the training of deeper Transformers, trained with LayerDrop 0.05 and pre-normalization.
How to effectively train model with billions of sentences?
Split the training data into 256 different shards to manage memory consumption.
Problem with direct splitting low-resource language into shards: Variability of each shard’s data for low-resource languages. Ex: language with only 25600 sentences would contain 100 sentences of a language direction per shard => the model would easily overfit.
Solution: Each language is divided into a different number of shards based on resource level. High resource have more shards and lowest resource languages only have one shard.
Mining Parallel Data
Efficient way to automatically create parallel data: Search for a sentence that could be a potential translation of sentence in a monolingual corpus (Comparable corpora) => Task of semantic similarity search on multiple languages.
Generate embeddings by any multilingual language model and perform similarity measure. The paper uses LASER embeddings and FAISS indexing to create corpora.
Postprocessing
- Remove sentences with >50% punctuation.
- Deduplicate data, remove sentences in train set if it appears in val/test set.
- Remove long sentences: >250 subwords after segmentation.
- Language-length filtering: remove sentences with length mismatch between source-translation > 3x
- Language-specific filtering: removes sentences that contain more than 50% of characters that have not been marked as core to the identified language.
Once we know how to mine parallel data, should we do this task for every combination of languages?
This should not be done:
- Due to the intensive computation required for all possible combination of pairs: 9900/2 = 4500 parallel corpora mining.
- Not all languages are linguistically related around the world. Ex: There are very slight chances of a population speaking both Marathi and Hebrew. However, there would be a huge population speaking Marathi and Hindi as they belong to same Indo-aryan family and are also geographically close.
Few groups from the paper with 3-4 bridge languages (BOLD) in each group
Hence, the authors proposed Sparse Mining: Mining only a subset of pairs using bridge languages.
- 100 Languages are grouped into 14 groups.
- Languages in each group are mined together. Ex: The Indo-Aryan family (Bengali, Gujarati, Hindi etc.) is mined together.
- To connect languages across different groups, 1–3 bridge languages in each group are chosen, usually those with most resources, such as Bengali, Hindi, and Tamil for the 12 languages in the Indo-Aryan family.
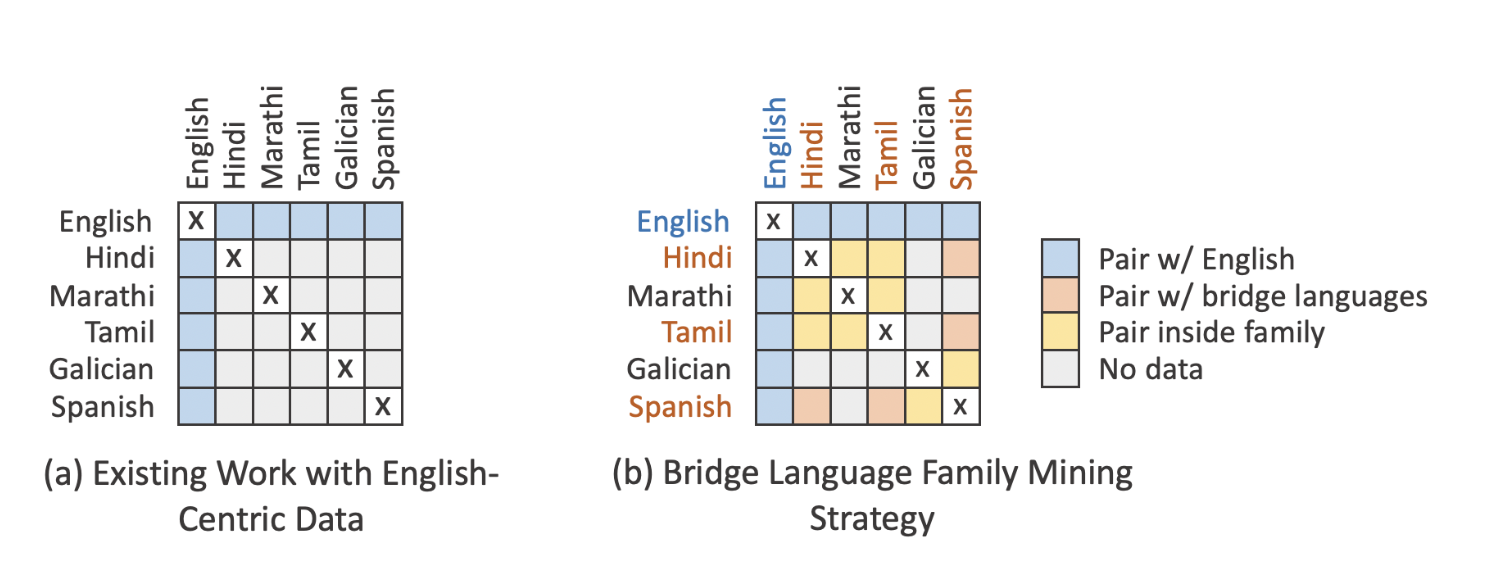
Depiction of an English-Only data mining setting compared to the Bridge Language Mining Strategy. The matrix (right) is neither fully random (dense), not English-centric (sparse). Bridge languages create a mix of sparse and dense matrix.
Refer to paper for performance analysis of various matrix settings. The results are validated by varying the randomness and sparsity of the language matrix.
Augmentation through Backtranslation
Backtranslation (BT) is widely used technique to supplement parallel data by obtaining synthetic translations of target data. Core idea: When training a model ($ M_1 $) to translate from a source language to a target language, backtranslation generates additional data by translating monolingual target sentences ($ T’ $) into the source language ($ S’ $).
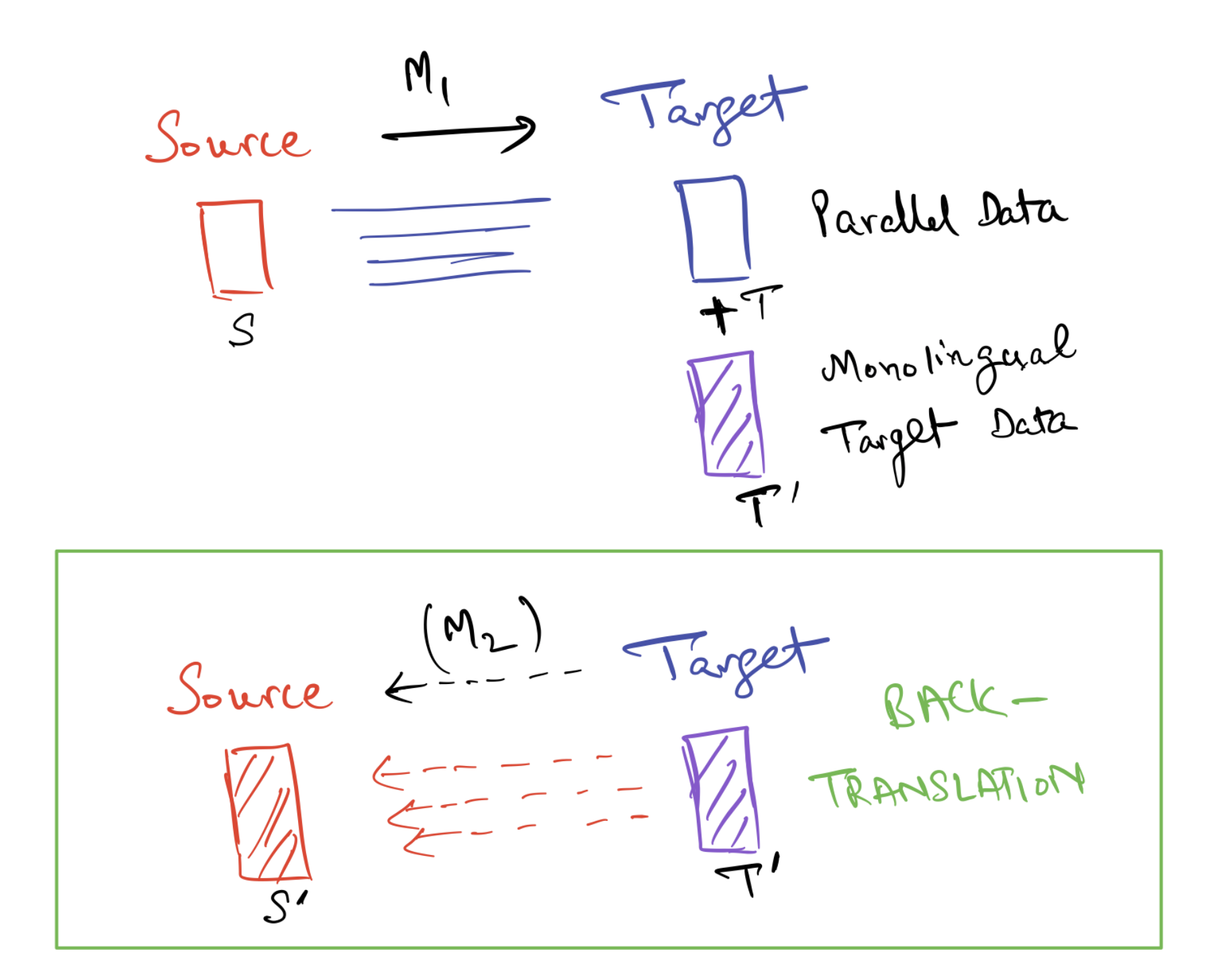 Original parallel data: (S) -> (T). Augmented Parallel Data: (S+S') -> (T+T')
Original parallel data: (S) -> (T). Augmented Parallel Data: (S+S') -> (T+T') Since back-translation is computationally intensive, the authors focus on BT in 100 directions with a BLEU score of between 2 and 10.Backtranslation almost always improves performance for any direction, regardless of the original BLEU score.
To be continued…