Highlights of AthNLP Summer School 2019 - Part II
This post discusses the highlights of Athens NLP Summer School 2019. The sessions covered core concepts on Language Modelling, Machine Translation, POS Tagging & Question Answering.

Table of Content
- NLP Application I: Machine Translation [PPT]
- NLP Application II: Machine Reading [PPT]
- NLP Application III: Dialog Systems [PPT]
The first part of this three-part post can be accessed here. The complete lecture playlist can be accessed here.
NLP Application I: Machine Translation [PPT]
Arianna Bisazza from University of Groningen gave an exciting talk on Machine Translation in NLP. We all encounter translation systems whether on social media (twitter/facebook) or while translating web pages. Machine Translation (MT) has come a long way from rule-based MT to statistical MT (SMT) to the recent neural MT (NMT). Refer to the slides and the talk for details about the history of MT.
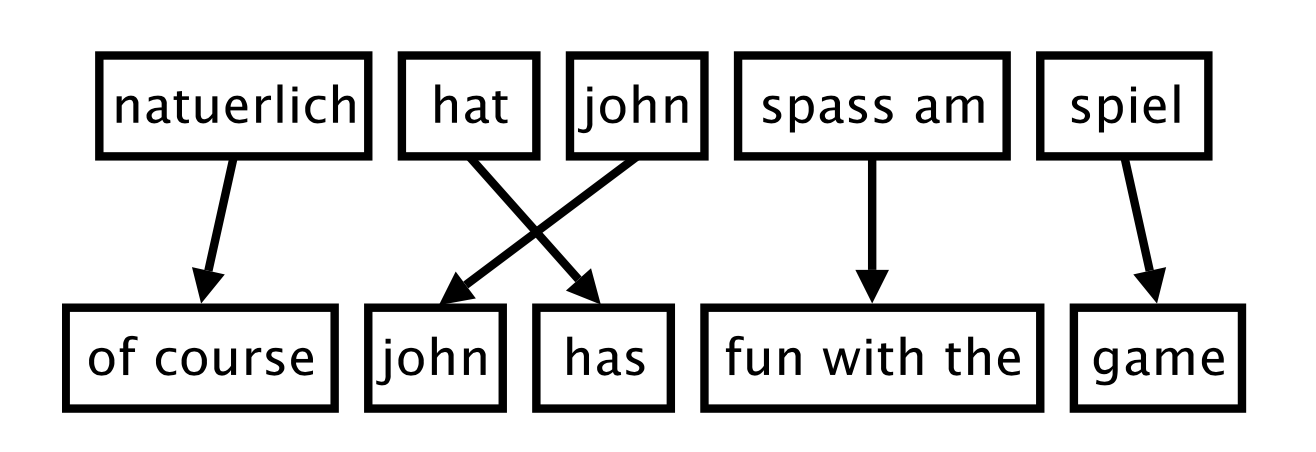
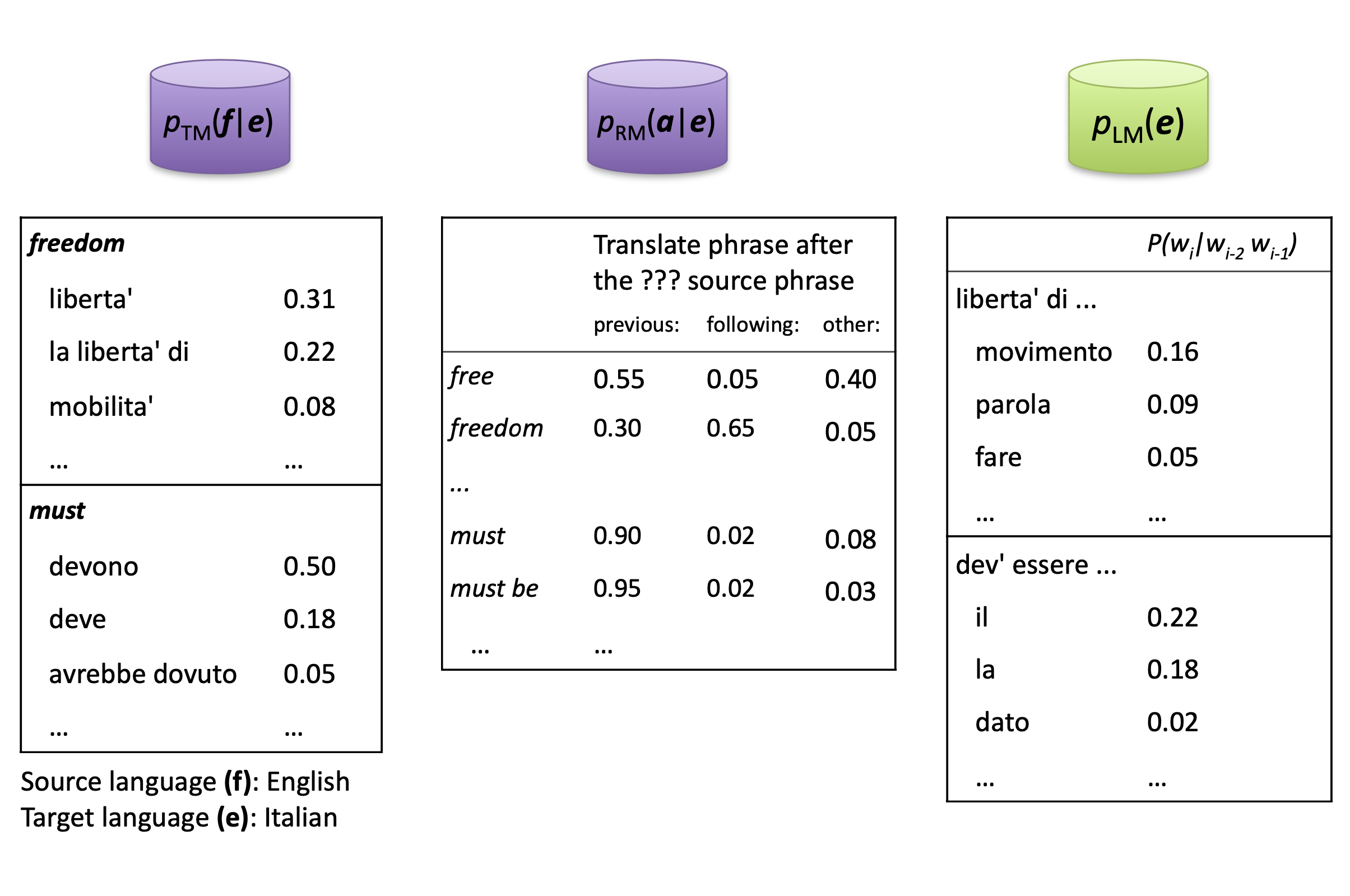
Earliest Phrase-based SMT approach inspired from cryptography adopted a noisy channel model to recover a message ($e^*$) from the distorted message ($f$) using bayes method which did not work very well for most text. The year 2000 saw a great progress in MT using the data-driven discriminative SMT approach. This introduced linear combination of features along with a phrase alignment variable which allowed phrases to be aligned in multiple ways while translating a piece of text. Flexibility in these models permitted incorporation of submodels, for example: phrase translation ($p_{TM}$) model, reordering models ($p_{RM}$),etc.
The rise of neural networks made all these approaches (feature engineering, multiple information from parallel data, submodels, etc.) obsolete as we now have a single end-to-end condition language model for both training and prediction. A basic sequence-to-sequence (Seq2Seq) NMT model consists of an encoder which maps the source text to a continuous-space sentence representation & a decoder which generates word-by-word translation from this continuous representation. RNN-based Seq2Seq NMT model adds a recurrent hidden state in both encoder and decoder that allows the model to capture the information in the input sequence into a fixed-length vector. But this approach does not work well for longer sequences. The arrival of attention mechanism resolved this problem by assigning attention weights to concentrate on most significant information. This gave rise to the popular transformer architecture which is currently driving huge progress in most NLP tasks.
NLP Application II: Machine Reading [PPT]
Sebastian Riedel from Facebook AI Research gave a lecture on Machine Reading in NLP, where he talked about .... Machine Reading can be described as converting any text into a meaningful representation which can then be used for satisfying various information needs. Think of this task as reading a passage of text and answering questions based on that text. This might seem an easy task for a human as we are good at linking prior information & making inferences. However, it becomes very problematic when training machines for the same.
Approaches such as semantic parsing, knowledge base construction, end-to-end reading comprehension have been used for meaningfully representing information. But some core challenges needs to be addressed while solving any machine reading task. Lets discuss them individually in the case of knowledge graph construction.
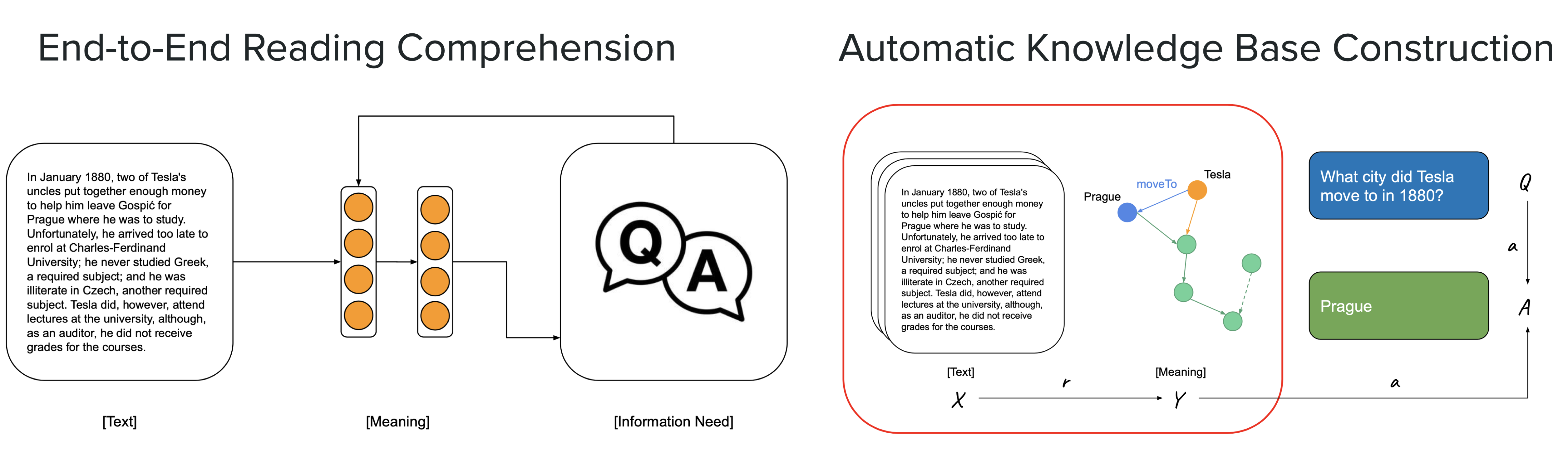
Automatic Knowledge base construction inputs a text and maps it onto a knowledge graph where the nodes represent the entities in the text and edges depict the relationship between those entities. This can be addressed simply as a sequence labelling task using either Conditional Random Fields (CRFs) or any RNN-based architectures.
Challenges:
-
Ambiguity: The model needs to understand the context for any recognizing the entity of the text. For ex: “Tesla” can be a person or a brand name depending upon the context.
-
Variation: A single sentence can be written in a lot of different ways. For ex: “I moved to Japan” and “I settled in Japan” reveal a similar meaning and hence should capture similar representations.
-
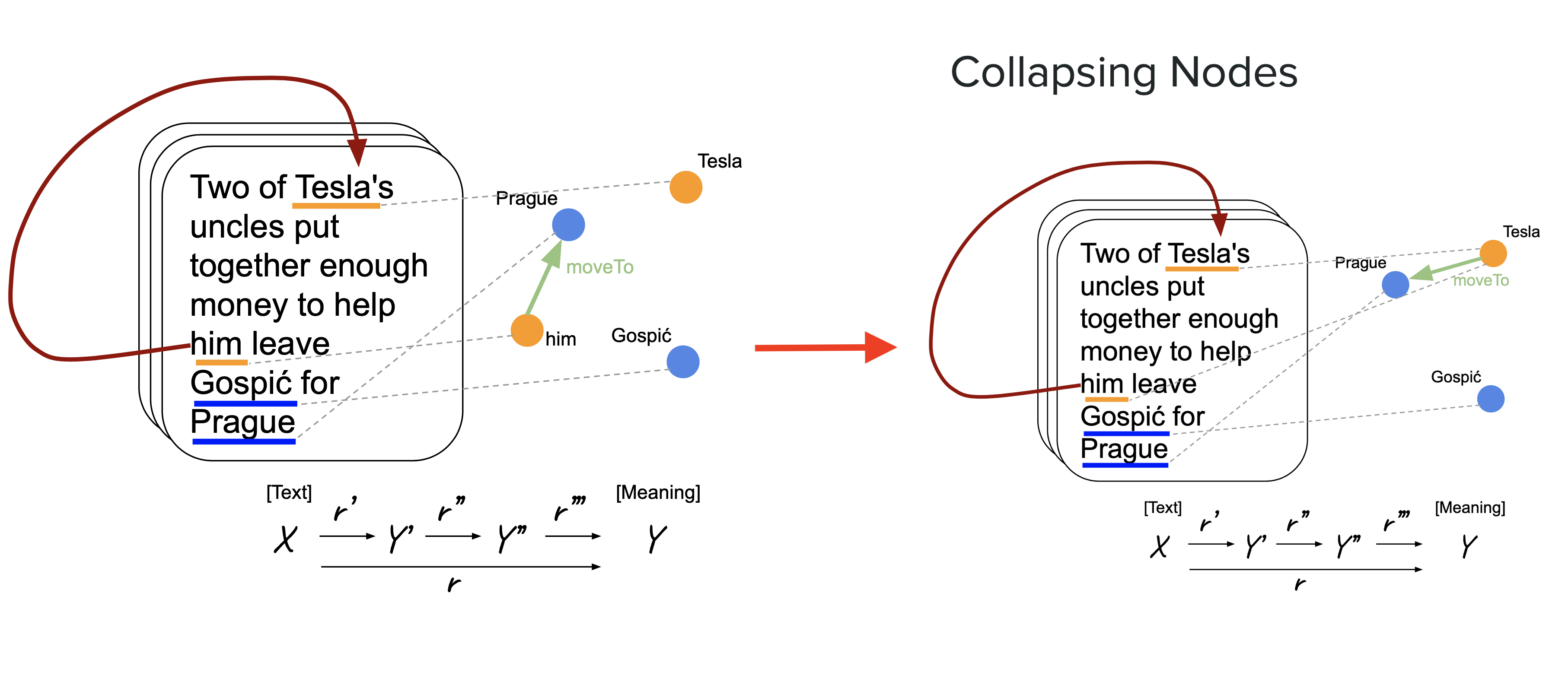
Coreference Resolution: In the text (Refer figure), the model knows that some pronoun (“him”) moved to prague but collapsing nodes and identifying this pronoun “him” belongs to “Tesla” is called coreference resolution.
In end-to-end reading comprehension, instead of building a knowledge graph, meaning representation is obtained directly from the input text using an end-to-end deep learning model. A general blueprint of this model looks like the Attentive Reader model (See fig.).
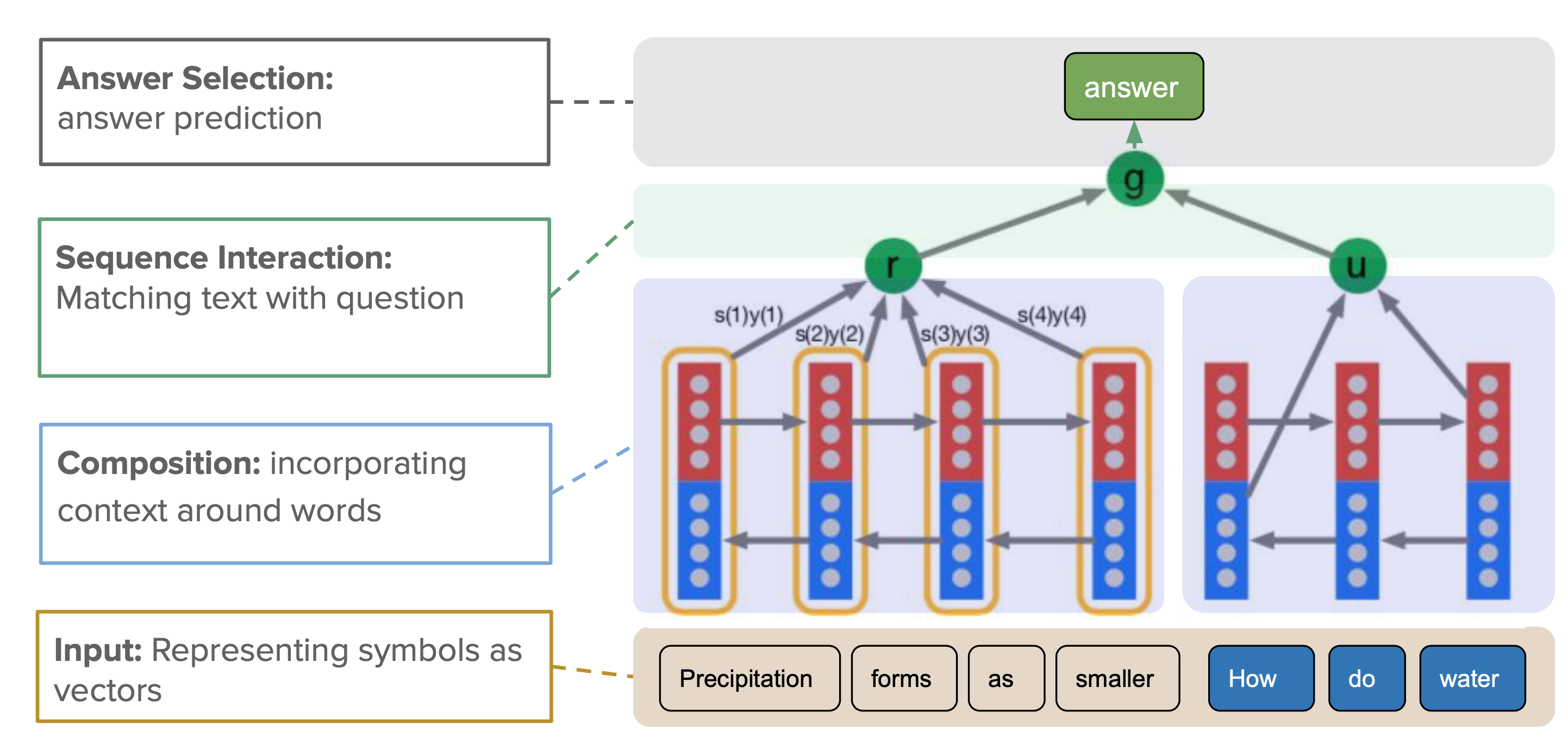
The input tokens are represented as embedding vectors and then composed in some form to contextualize the surrounding information. Sequential interaction module is then used to combine the contextualized info about the text and the question into a joint representation to predict the answer.
NLP Application III: Dialog Systems [PPT]
The convenience of voice as a communication medium along with the advancement in automatic speech recognition (ASR) technology has led to a huge surge in voice recognition systems. These systems can mainly be categorized as:
- Social chit-chat systems: The objective in chit-chat systems is to focus on better engagement and longer responses with the user.
- Task-oriented dialogue systems: Priority is to provide brief and succinct responses. Eg: asking a question (information consumption) or scheduling a meeting (task completion).